
Testing
AS Textbook reference page 99-102
|
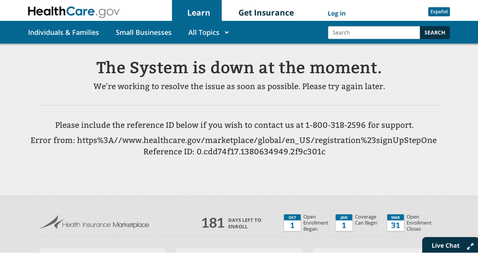
With large software projects, testing is often given to a separate group of people who may not be programmers. Their job is to test the code thoroughly before it is released.
Sometimes this happens ... sometimes it doesn't. |
|
Three different types of test
Dry-run testing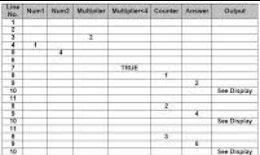
In dry run testing, no actual computer is used. Instead the tester runs through the documented algorithms on paper, usually in the form of a 'trace table' to work out exactly what the state of the program will be for each possible input.
|
Black-box testing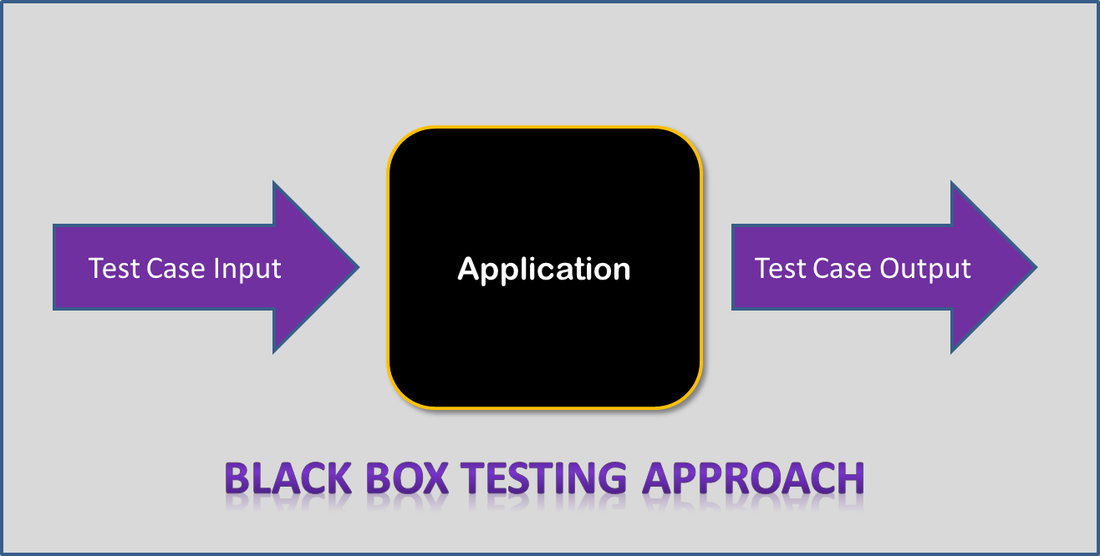
In 'black-box' testing there is no attempt to understand the inner workings of the code. Instead a range of possible inputs are fed into the computer and the outputs are compared with the expected and desired results.
|
White-box testing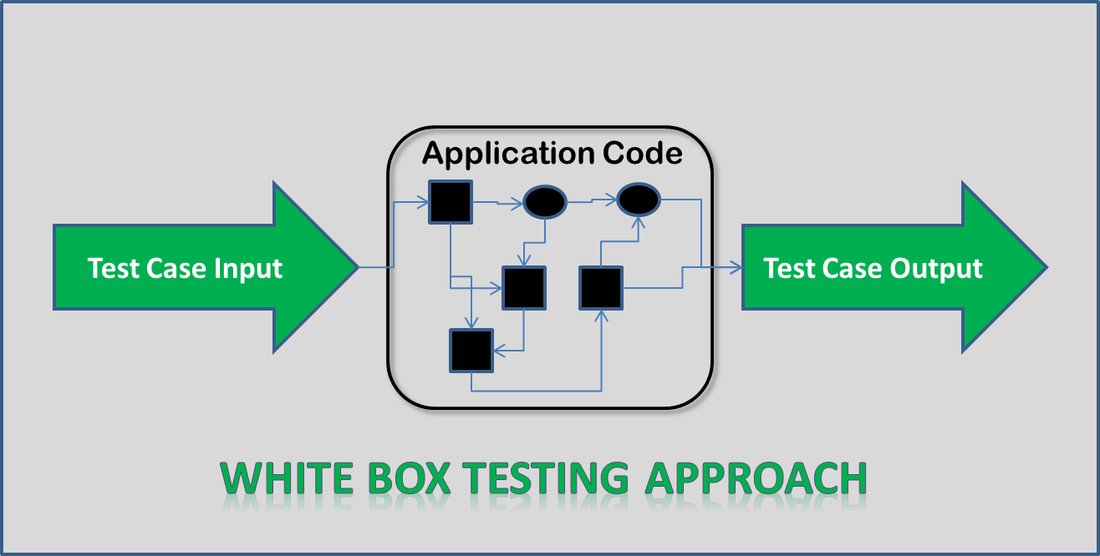
White box testing does use knowledge of the code and the system's structure to design tests (again comparisons of input with expected outputs) that put pressure on individual components within the code.
|
Selection of test data
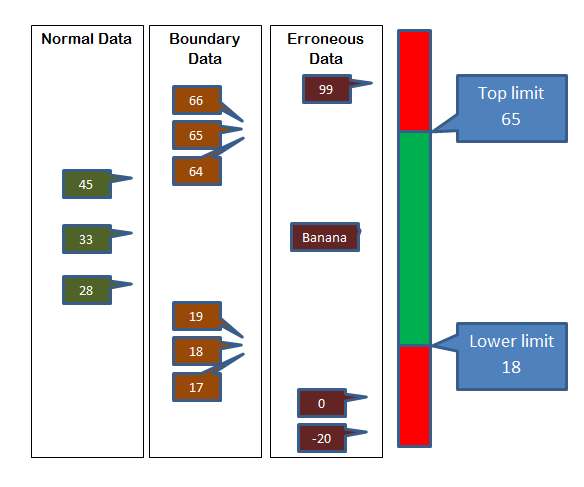
Imagine a program that requires the age of a person applying for insurance. The acceptable age range of input is from 18 to 65.
Normal dataData values such as 35, 50 and 44 would be normal data. This is well within the acceptable range and should be accepted.
Boundary dataData values 17,18 are boundary data. Processing should be different for these two. As a general rule, errors are most likely on the boundary between two process paths.
Erroneous dataErroneous data is just wrong and should be cleanly rejected by the system (without causing a crash). Because there are lots of different ways in which data can be in error, tests of some sophistication are needed.
|
|
Visualisation of 500,000,000 lines of code
Types of validation check
|
